It took me quite an effort to make Tensorflow bidirectional Recurrent Neural Network Text summarization model running on my own NVIDIA graphic card. Many documentations online were helpful, however, none of them was comprehensive. Therefore I write this tutorial to shed some light for my future reimplementation. If you like it, please feel free to share.
0. Hardware and Software
Software
Operating System: Ubuntu Linux 16.04 64-bit (I also successfully tried on Mac OS but this tutorial specifies for Ubuntu Linux)
Tensorflow r0.11
Python 2.7
Nvidia CUDA 8.0
NVIDIA cuDNN 5.1
Hardware
GPU: Geforce GTX 970 4G
CPU: AMD Phenom II X6 1055T
Memory: 8G
Stage 1: Install NVIDIA CUDA and Tensorflow
I first followed NVIDIA website tutorial but ran into an issue that the system kept asking to me reboot because of Nouveau package. Later I found this great article on askubuntu.com and the answer given by clearkimura solved my issues. It was clearkimura’s intellectual work, and to make this tutorial self-contained I will refer all the steps here and tweak it for new software versions.
1.1 Download CUDA
From NVIDIA website select Linux, x86_64, Ubuntu 16.04, and runlocal(file). This will download a “cuda_8.0.44_linux.run” file to local disk.
1.2 Installation Preparation of CUDA
The official website tells us to execute
sudo sh cuda_8.0.44_linux.run
for installation, but that may not work because of X-server and Nouveau issue. Here are the preparation steps I made it work:
sudo apt-get install build-essential sudo vi /etc/modprobe.d/blacklist-nouveau.conf
Then, add the following line in that file: blacklist nouveau option nouveau modeset=0
sudo update-initramfs -u
Then reboot the computer.
At login screen, press Ctrl+Alt+F1 and login to user (needs sudo).
Go to the directory where you have the CUDA driver, and run:
chmod a+x . sudo service lightdm stop sudo bash cuda-8.0.44_linux.run --no-opengl-libs
1.3 CUDA Installation
During the install –
- Accept EULA conditions
- Say YES to installing the NVIDIA driver
- Say YES to installing CUDA Toolkit + Driver
- Say YES to installing CUDA Samples
- Say NO rebuilding any Xserver configurations with Nvidia
Check if /dev/nvidia* files exist. If they don’t, do the following –
sudo modprobe nvidia
Set Environment path variables –
export PATH=/usr/local/cuda-8.0/bin:$PATH export LD_LIBRARY_PATH=/usr/local/cuda-8.0/lib64:$LD_LIBRARY_PATH
Verify the driver version –
cat /proc/driver/nvidia/version
Check CUDA driver version
nvcc –V
Switch the lightdm back on again
sudo service lightdm start
Ctrl+Alt+F7 and login to the system through GUI
Create CUDA Samples –
- Go to
NVIDIA_CUDA-8.0_Samplesfolder through terminal -
make
-
cd bin/x86_64/linux/release/
-
./deviceQuery
-
./bandwidthTest
- Both tests should ultimately output a ‘PASS’ in terminal
Reboot the system.
1.3 NVIDIA cuDNN Installation
Once the CUDA Toolkit is installed, download cuDNN v5.1 Library for Linux (note that you will need to register for the Accelerated Computing Developer Program).
Once downloaded, uncompress the files and copy them into the CUDA Toolkit directory (assumed here to be in /usr/local/cuda/):
sudo tar -xvf cudnn-8.0-linux-x64-v5.1-rc.tgz -C /usr/local
1.4 Install and upgrade PIP
sudo apt-get install python-pip python-dev pip install --upgrade pip
1.5 Install Bazel
To build TensorFlow from source, the Bazel build system must first be installed as follows. Full details are available here.
$ sudo apt-get install software-properties-common swig $ sudo add-apt-repository ppa:webupd8team/java $ sudo apt-get update $ sudo apt-get install oracle-java8-installer $ echo "deb http://storage.googleapis.com/bazel-apt stable jdk1.8" | sudo tee /etc/apt/sources.list.d/bazel.list $ curl https://storage.googleapis.com/bazel-apt/doc/apt-key.pub.gpg | sudo apt-key add - $ sudo apt-get update $ sudo apt-get install bazel
1.6 Install TensorFlow
To obtain the best performance with TensorFlow we recommend building it from source.
First, clone the TensorFlow source code repository:
$ git clone https://github.com/tensorflow/tensorflow $ cd tensorflow
Then run the configure script as follows:
$ ./configure Please specify the location of python. [Default is /usr/bin/python]: [enter] Do you wish to build TensorFlow with Google Cloud Platform support? [y/N] No Google Cloud Platform support will be enabled for TensorFlow Do you wish to build TensorFlow with GPU support? [y/N] y GPU support will be enabled for TensorFlow Please specify which gcc nvcc should use as the host compiler. [Default is /usr/bin/gcc]: Please specify the Cuda SDK version you want to use, e.g. 8.0. [Leave empty to use system default]: Please specify the Cudnn version you want to use. [Leave empty to use system default]: Please specify the location where cuDNN 5 library is installed. Refer to README.md for more details. [Default is /usr/local/cuda]: Please specify a list of comma-separated Cuda compute capabilities you want to build with. You can find the compute capability of your device at: https://developer.nvidia.com/cuda-gpus. Please note that each additional compute capability significantly increases your build time and binary size. [Default is: "3.5,5.2"]:5.2,6.1 [see https://developer.nvidia.com/cuda-gpus] Setting up Cuda include Setting up Cuda lib64 Setting up Cuda bin Setting up Cuda nvvm Setting up CUPTI include Setting up CUPTI lib64 Configuration finished
Then call bazel to build the TensorFlow pip package:
bazel build -c opt --config=cuda //tensorflow/tools/pip_package:build_pip_package bazel-bin/tensorflow/tools/pip_package/build_pip_package /tmp/tensorflow_pkg
And finally install the TensorFlow pip package
$ sudo pip install --upgrade /tmp/tensorflow_pkg/tensorflow-0.9.0-*.whl
1.7 Test your installation
To test the installation, open an interactive Python shell and import the TensorFlow module:
$ cd $ python … import tensorflow as tf I tensorflow/stream_executor/dso_loader.cc:105] successfully opened CUDA library libcublas.so locally I tensorflow/stream_executor/dso_loader.cc:105] successfully opened CUDA library libcudnn.so locally I tensorflow/stream_executor/dso_loader.cc:105] successfully opened CUDA library libcufft.so locally I tensorflow/stream_executor/dso_loader.cc:105] successfully opened CUDA library libcuda.so.1 locally I tensorflow/stream_executor/dso_loader.cc:105] successfully opened CUDA library libcurand.so locally
Stage 2: Install Tensorflow Text Summarization Model
2.1 Download and Compile Tensorflow Models
Download the tensorflow models from https://github.com/tensorflow/models and extract it your local folder.
$git clone https://github.com/tensorflow/models ~/models
The Tensorflow text summarization model is in textsum directory, which is based on the sequence to sequence attention model. Tensorflow did not publish paper about this implementation, but the underlying theory is very similar to these two papers published by Facebook and IBM (literature review credit goes to the contributors in this Quora discussion).
During my own implementation, I found it was necessary to update some lines according to this fix to fully enable GPU. Also, in seq2seq_attention.py, I changed “/cpu:0” of Training function to “/gpu:0”. If the tf.device is set to CPU, the model training takes very long time and I believe it does not use the power of GPU.
def _Train(model, data_batcher):
"""Runs model training."""
with tf.device('/gpu:0'):
Since bazel and cuda have been setup before, it is ready to compile the TextSum model with CUDA support.
$cd models $mkdir traintextsum $cd traintextsum $ln -sf ../textsum/ . $mkdir data $touch WORKSPACE $bazel build -c opt --config=cuda textsum/...
After compilation, it is time to prepare the text files for model training.
2.2 Preparation of Training Corpora using Toy Data
Tensorflow doesn’t provide the original Gigaword dataset due to license restriction. It ships a toy dataset (two files, ‘data’ and ‘vocab’ in the data folder) containing 21 articles and abstracts to illustrate the format requirements. Though this toy data is far too small to train any meaningful models, it is still helpful to validate the setup and understand the working mechanism of the model.
The ‘data’ file provided on Github is binary format, so it is convenient to transform back to text format.
$python data_convert_example.py --command binary_to_text --in_file data/data --out_file data/text_data
From the text file ‘text_data’, cut and paste the first article and save that single article as ‘text_data_test’. This single article is the test data which looks like:
article=
the sri lankan government on wednesday announced the closure of government schools with immediate effect as a military campaign against tamil separatists escalated in the north of the country . the cabinet wednesday decided to advance the december holidays by one month because of a threat from the liberation tigers of tamil eelam -lrb- ltte -rrb- against school children , a government official said . “ there are intelligence reports that the tigers may try to kill a lot of children to provoke a backlash against tamils in colombo . “ if that happens , troops will have to be withdrawn from the north to maintain law and order here , ” a police official said . he said education minister richard pathirana visited several government schools wednesday before the closure decision was taken . the government will make alternate arrangements to hold end of term examinations , officials said . earlier wednesday , president chandrika kumaratunga said the ltte may step up their attacks in the capital to seek revenge for the ongoing military offensive which she described as the biggest ever drive to take the tiger town of jaffna . .
abstract=
sri lanka closes schools as war escalates .
publisher=AFP
Save the remaining 20 articles in the ‘text_data’ as ‘text_data_train’. This will be the training data.
Transform the training and test text file to binary format using command:
$python data_convert_example.py --command text_to_binary --in_file data/text_data_train --out_file data/bin_data_train $python data_convert_example.py --command text_to_binary --in_file data/text_data_test --out_file data/bin_data_test
Another critical component is the vocabulary, as pointed out by xtr33me in this post, the shipped vocabulary from tensor flow does not match the toy data set. This means there are many unseen words in the toy data set, and will result in symbol for unseen words in decoding. Please follow this link to download the expanded vocabulary, and replace all occurrences of old ‘vocab’ file in textsum and triaintextsum folders.
2.3 Model Training and Parameters Setting
The model can be trained using the default parameters setting configured in the script. From the command line, execute the bazel command:
# Run the training
bazel-bin/textsum/seq2seq_attention \
--mode=train \
--article_key=article \
--abstract_key=abstract \
--data_path=data/bin_data_train\
--vocab_path=data/vocab \
--log_root=textsum/log_root \
--train_dir=textsum/log_root/train
The command line parameters are:
- mode – specify model training, other options are evaluate and decode
- article_key – the tag indicating article labels in the text
- abstract_key – the tag indicating summarized abstract labels in the text. In Gigaword text, it is set as ‘headline’
- data_path – the file path for binary training data
- vocab_path – the file path for vocabulary data (text file)
- log_root – the directory path to store the logs. Textsum algorithm frequently saves intermediate steps in the log_root directory.
- train_dir – the directory to output model training summary
There are also model training parameters specified in python code seq2seq_attention.py:
- max_run_steps – the maximum number of epochs to train
- max_article_sentences – Tensorflow Textsum model only uses the first 2 sentences of an article for training, under assumption that the first 2 sentences contain enough information for summarization. This assumption may be true for newsgroups, however, may not be general enough for other type of tasks. At this moment I am not clear about the feasibility and impact to increase this value in model training.
- max_abstract_sentences – Tensorflow Textsum model only uses the first 100 words of abstracts as target words to train the model. Similarly, feasibility and impact of increasing this value needs further investigation.
- beam_size – The beam_size limits the number of potential sequences to be searched for optimal summarization. An analogue to this is the number of optimal & suboptimal sequence generated by Dynamic programming (Viterbi algorithm). For example, when the beam_size is 4, the decode algorithm will generate 4 best summaries.
- eval_interval_secs – By default is 60 secs. Evaluation is running simultaneously at model training time to monitor the quality of training process.
- checkpoint_secs – During training, the algorithm frequently outputs intermediate results to log_root folder. This parameter controls the outputting frequency. It is not clear whether the algorithm can use previously saved states to continue training.
- num_gpus – The number of GPU. For multi-gpu settings, this number should be larger than 1 to fully unleash the power. Normally it should be 1.
- minimum learning rate & learning rate – These two parameters are set in seq2seq_attention_model.HParams. For nerual network training, these are important hyper-parameters that affect the convergence.
- Encoder layers – number of layers in neural network
- num_hidden – number of RNN cells
- emb_dim – the dimensionality of word embeddings
2.4 Training time for Toy data (3 hours for 5K epochs)
Using single Geforce GTX 970 GPU, setting training epoch to 5000, model training on 20 toy data articles took about 180 minutes. The running average loss decreased to the level 0.001 (Figure). Given the fact that my GPU is a 2 year old moderate model, I believe better GPU platform can train the same model much faster.
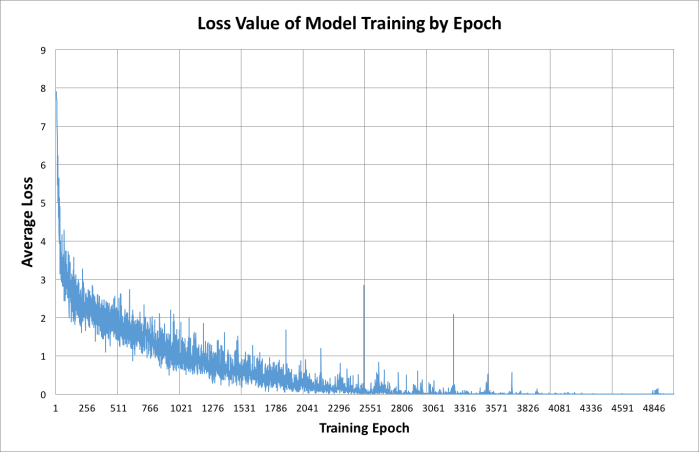
2.5 Text Summarization Results on Toy data
To apply the trained model to summarize articles, run the decoding function in bazel as:
# Run the training
bazel-bin/textsum/seq2seq_attention \
--mode=decode \
--article_key=article \
--abstract_key=abstract \
--data_path=data/bin_data_test\
--vocab_path=data/vocab \
--log_root=textsum/log_root \
--decode_dir=textsum/log_root/decode \
--beam_size=4
Note that the ‘data_path’ parameter is specified as the binary test data created earlier, which contains a single article. The ‘decode_dir’ parameter specifies the output directory. It is still unclear how Textsum model actually does the decoding, and even for a single article the decode function never stops and keeps refreshing the output. And for a single article there are usually multiple lines of output. To keep trace of the outputs, Textsum decoding function generates a pair of files, for instance:

decode* is the predicted summarization, and ref* is the manual summarization provided for training/validation. In this way, one can associate the corresponding lines of prediction with the original article and keep trace of them.
I first checked the predicted summarization for the test article, because it has only one, I just check the head of the prediction result file:
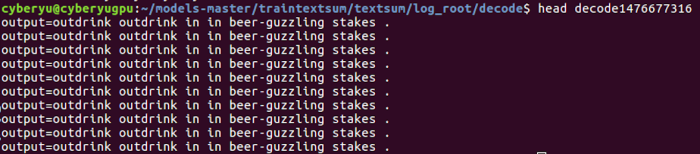
And the true summarization should be:
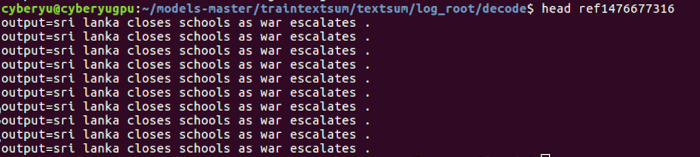
Clearly, the automate summarization makes little sense. And previous users have reported similar issues. This is mainly because the toy data doesn’t have enough text to train the complicated RNN model. To generalize this model, we need much larger training data.
Alternatively, I apply the same model back to the training data, using command:
# Run the training
bazel-bin/textsum/seq2seq_attention \
--mode=decode \
--article_key=article \
--abstract_key=abstract \
--data_path=data/bin_data_train\
--vocab_path=data/vocab \
--log_root=textsum/log_root \
--decode_dir=textsum/log_root/decode \
--beam_size=4
Though the results do not represent generalized performance of model, it does help to validate the summarization performance somehow. I list out the original abstract with the predicted summarization as follows (the blue text is original abstract, and the red text is predicted summarization):
- czechs outdrink germans in beer-guzzling stakes . outdrink outdrink germans in beer-guzzling stakes .
- abb to sell electrical explosion-proof equipment business . to sell electrical explosion-proof explosion-proof equipment business .
- malaysia says apec to blame for farm stalemate . says apec apec to blame for farm stalemate .
- injury worry for sampras . worry for sampras .
- gerry adams returning to us for peace process support . gerry adams returning to us for peace process support .
- closure of territories to be partially lifted tuesday . of territories territories to be partially lifted tuesday .
- argentine to extradite nazi ss captain to italy . to to extradite nazi ss captain to italy .
- arafat doubts gaza attack will affect redeployment . doubts gaza attack will affect redeployment .
- us firm bids #.# billion pounds for seeboard . serb firm bids #.# billion pounds for seeboard .
- crimean parliament adopts new constitution . parliament adopts new constitution . .
- leaders begin arriving for commonwealth summit . leaders begin arriving for commonwealth summit .
- mexican financial markets end turbulent week . financial financial markets end turbulent week .
- serb army accuses police of pulling back from front lines . army accuses accuses police of pulling back from front lines .
- brazilian families to get reparations for military regime killings . families to to reparations reparations for military regime killings
- us agency to approve new anti-aids drugs . agency to to new new anti-aids drugs .
- scorecard in australia-pakistan cricket test . in australia-pakistan cricket test .
- croatians vote in three constituencies . vote in in constituencies constituencies .
- six voted us athletics honor . voted voted athletics honor honor .
- opposition activists paralyse calcutta . activists paralyse calcutta .
- moslem rights group wants narcotic khat legalised . rights rights group wants narcotic khat legalised .
As shown, when applying trained model back to training data, the predicted summarizations generally sound OKAY, given the fact I only trained the model for 5000 epochs. However, it seems Named Entities still cause challenges, especially nation names are involved. Since I haven’t fully studied the model code yet, I can only vaguely assume that linguistic features such as Named Entities, POS-tag features (Proper nouns), etc. might help improving the abstracted summarization.
In a nutshell, this tutorial elaborates how to get things running on a desktop GPU platform using Tensorflow Sequence-to-Sequence attention model for text summarization. As mentioned before, it is very helpful to digest the code along with reading the Facebook and IBM papers published about this approach. More importantly, meaningful results can only be obtained on training large-scale curated data sets (with human summarizations) on high-performance computation platforms.

Well written post here and I only wish I had a reference like this when I first started playing with Textsum. Thanks for providing this as it will be very beneficial for others!
LikeLike
Thank you Daniel! I will keep following up with new updates about this topic.
LikeLike
greatly useful comment to help me start exploring tf. BTW may I know if you have tried creating your own dataset for implementation?
LikeLike
Hardly, please check my new follow up post. Text summarization is still very slow even on the most advanced computational platform.
LikeLike